


Parallel Computing
Lab Facilities
Since 1998, the Wabash College Computational Chemistry Lab has utilized parallel computing to study the molecular modeling of biological membranes using all-atom (fine grain) simulations. With the development of open source libraries, Rocks cluster management and Linux support, and diversifying application and community development, molecular modeling has become possible for a larger audience and is no longer restricted to facilities and budgets that large computing labs provide. Evolving technology, advances in hardware engineering, and new and optimized simulation techniques continue to provide a changing landscape of opportunities.
Several students use the lab facilities in conjuction with independent research projects under the supervision of professor Feller. The lab was also made available for a course in parallel programming started by retired computer science professor David Maharry. Students ran parallel programs that they wrote as class assignments.
|
|
|
After retiring some well used equipment, the lab employs three high performance clusters and a GPU accelerated workstation. Funds for these installments were provided by Wabash College and a NSF Research at Undergraduate Institutions grant to Scott Feller. The cluster setup allows adaptability and simplified management, and allows the whole cluster to operate as a single machine, a virtual supercomputer.
| rocks2 | Rocks 5.1 (CentOS 5.2) | 32 compute nodes, 64 cores, Dell PowerEdge SC1425 2x Intel Xeon Irwindale @ 2.8GHz, 2GB shared memory, and 2 cores per node networking: 10Gbps Infiniband, Gigabit |
| rocks3 | Rocks 5.0 (CentOS 5.1) | 5 compute nodes, 80 cores, Dell PowerEdge R905 4x AMD Opteron 8350 @ 2.0 GHz, 8 GB shared memory, and 16 cores per node networking: Gigabit |
| rocks4 | Rocks 5.3 (CentOS 5.4) | 8 compute nodes, 192 cores, Dell PowerEdge R810 4x Intel Xeon E7540 @ 2.0 GHz, 32 GB shared memory, and 24 cores per node networking: 40 Gbps Infiniband, Gigabit |
| teslarocks
(*standalone GPU workstation) |
Rocks 6.0 (CentOS 6.2) | Thinkmate GPX XS8-2460-4GPU (Supermicro SuperServer 7047GR-TRF)
2x Intel Xeon E5-2665 @ 2.40GHz, 16GB shared memory, and 16 cores 4x GTX580 graphic accelerators, 2048 (combined) Cuda cores @ 772MHz, and 6GB (combined) graphics memory |
The clusters have more than 300 cores available with each cluster having an optimized workload to match cluster size and networking speed. The rocks2 cluster is now the oldest and is capable of accelerating two concurrent simulations. This cluster also acts as a central hub for the lab, containing additional software and expanded shared storage and backup. The rocks3 cluster was designed to minimize cost, using a standard Gigabit switch. This was the lab's first cluster to utilize multiple, multi-core processors in a server. Simulations are efficiently run by using all the cores on one physical server, with five such concurrent simulations possible. The GPU accelerated workstation is capable of the fastest single simulation acceleration in the lab using NAMD. (GPU support is under development in CHARMM.) With processor advances, the highest capacity, and fast networking, the rocks4 cluster is capable of handling many simulations with high acceleration. It has a sizeable advantage when running a replica exchange simulation. This technique creates a spectrum of simulations with a variable condition or restraint (such as temperature) and provides enhanced sampling by letting the molecules cross energy barriers in the different replicas.
Thinking in Parallel
Parallel processing can be likened to a divide and conquer technique. A task is partitioned across multiple resources and the efficiency is determined by the interdependency of all the pieces. Accelerating a job in parallel is about balancing networking resources and processor speed. Networking resources, defined by bandwidth (or throughput) and latency, are easily identified as the weak link in the parallel execution of membrane simulations using molecular dynamics.
Parallel scaling suffers from the law of diminishing returns: the benefit from adding more CPU cores keeps getting less and less. For any practical application there is a critical point where the speedup from using more cores is matched by the increased cost of networking. After this point adding more cores will saturate your network resources and start make the parallel job run slower. The maximum scaling for our clusters running an average size CHARMM simulation is
Modeling Efficiency
 |
What is the best way to speed up parallel execution? Amdahl's model describes the general case for scaling efficiency. Let P be the the percentage of computations that can be done in parallel, N be the number of cores, and t be the time for serial execution. Then the amount of time to execute the parallel portion is t(P/N) and the time for the non-parallel portion is t(1-P). The expected speedup is then serial execution time/parallel execution time = and on the left are some sample values on a log plot. You can now see the limits to parallel execution. The curve for any value of P < 100% appears to asymptotically approach a maximum practical speedup. |
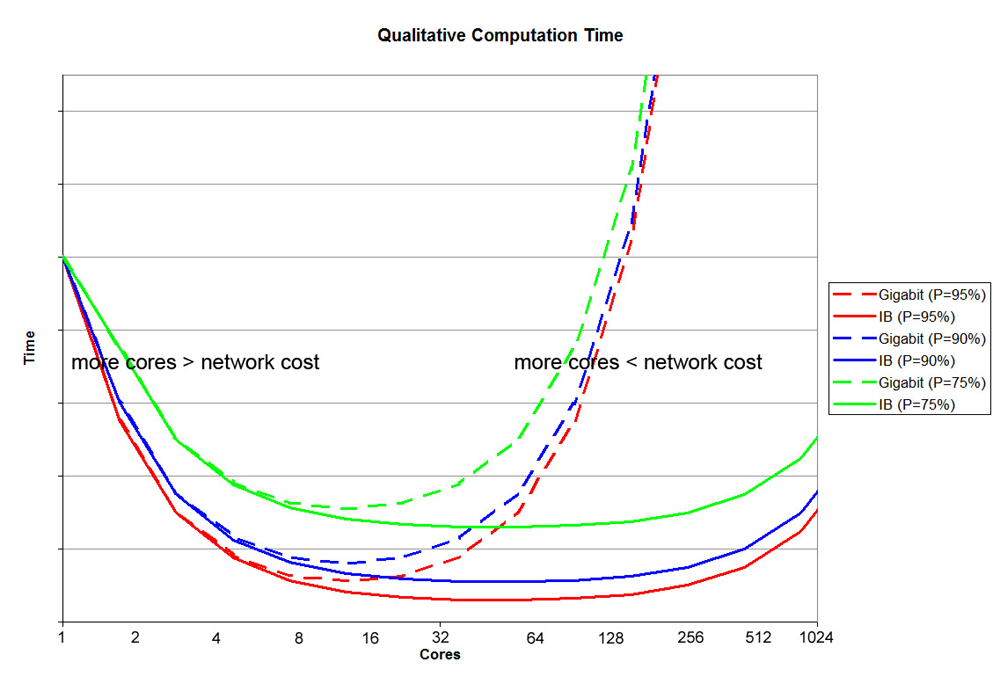
Now consider a somewhat oversimplified alteration to the above equation. Add a term, Nα, to simulate network broadcasting to the parallel execution time where α=size in memory/network bandwidth. That is, α measures the time to transfer the job over the network and Nα rougly measures the time to update the composite simulation by sending a copy the simulation to each CPU. We now have the equation
serial execution time/parallel execution time = 1/(1-P)+(P/N)+Nα
Consider the results for a case where size in memory is 128 MB (estimate for CHARMM simulaiton with 40,000 atoms), Gigabit bandwidth is 128 MB/s, and InfiniBand bandwidth is 40 GB/s. You can qualitatively see the expected diminishing returns for our Rocks clusters.
What is the best way to speed up parallel execution? The answer is to improve you algorithm to increase P. You should shift curves instead of moving along a curve to see the biggest gains. However, it is often the case that the subject to be investigated puts limits on available P curves.
 |
 |
Back to home page.